


NTTデータ
技術開発本部
副本部長
山本修一郎
他の分析手法との比較
構造化分析手法やUMLなどでも、アクタやタスク、資源を記述することはできる。しかしこれらの手法では、利害関係者としてのアクタはあくまでもシステムの外部にあってシステムを規定する存在なのであって、アクタ間の関係やビジネスゴールとの関係を明示的に記述することはできない。
具体的にUMLとSDモデルを比較すると次のようになる。
UMLのユースケース図では、アクタとユースケースの関係を記述する。しかしアクタ間の関係は一般化だけであって、ゴールに関するアクタ間の依存関係は記述できない。またユースケースは機能を表現しており、タスクに対応すると考えられる。ソフトゴールや資源に対応する図形要素はユースケース図にはない。SRモデルのような依存関係の貢献レベルを評価するラベルもユースケース図にはないので、ソフトゴール間の優劣をユースケース図では表現できない。
分析図としての記述能力を比較するならば、ユースケース図をSDモデルで表現できるが、ユースケース図では、ゴールやゴール間の依存関係は記述できない。この理由はユースケース図がシステムの機能を表現するために必要な情報だけを表現しているためである。これに対してSDモデルでは、アクタ間の依存関係のようなシステム機能の外部ではあるが、機能がなぜ必要なのかを説明する情報を記述している。
iスター・フレームワークでは、このようにアクタ間のソフトゴールと非機能に関する分析がより重要である。この点がiスター・フレームワークなどの非機能分析手法やゴール指向分析手法と従来の要求分析手法との大きな違いである。
ゴール指向分析手法とUMLや構造化分析手法は目的が異なるので、相補的に組み合わせて使うことができる。たとえば、SDモデルとSRモデルを用いて、まずゴール分析を実施する。この結果から、アクタとタスクや資源との関係が具体化できるので、ユースケース図でアクタとシステム機能の関係を記述するのである。この場合、SDモデルとユースケース図の追跡性を保障するためには、アクタの対応関係と、タスクとユースケースの対応関係を整理しておく必要がある。
同様に、構造化分析とiスター・フレームワークの組み合わせも考えられる。構造化分析ではデータフロー図で業務システムを分析する。データフロー図では、外部環境として、アクタだけでなく外部システムも記述し、外部環境とシステムの入出力データの関係を、プロセスによる入力データの出力データへの変換の系列により記述する。このとき保存されるデータについてはデータストアで記述する。SDモデルとデータフロー図の対応関係は次のようになるだろう。SDモデルのタスクをデータフロー図のプロセスとし、資源をデータフローやデータストアに対応づけることができる。SDモデルのゴールやソフトゴールに相当する記述要素はデータフロー図にはない。
構造化分析手法では、データフロー図で現状モデルをまず分析し、課題を明らかにすることで将来モデルを作成する。しかしデータフロー図にはなぜそのプロセスやデータが必要なのかといったゴールに関する記述はできない。このようなシステムの背景知識をSDモデルによって記述できるので、構造化分析手法を次のようにして拡張できるだろう(図5)。
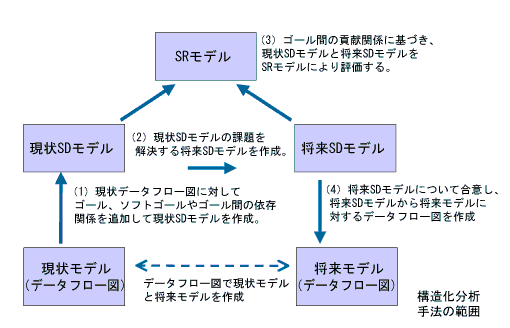
図5 構造化分析手法の拡張
- (1)現状データフロー図に対してゴール、ソフトゴールやゴール間の依存関係を追加して現状SDモデルを作成
- (2)現状SDモデルの課題を解決する将来SDモデルを作成
- (3)ゴール間の貢献関係に基づき、現状SDモデルと将来SDモデルをSRモデルにより評価する
- (4)将来SDモデルについて合意し、将来SDモデルから将来モデルに対するデータフロー図を作成
このような拡張手法の利点として、システム機能の存在理由をゴールに基づいて明記できるだけでなく、SDモデルのレベルで、機能よりも抽象度の高い議論によって将来モデルを記述できることと、SRモデルにより将来モデルの優位性を確認できるので手戻りを抑止できることが挙げられる。
iスター・フレームワークの留意点
前回も指摘したことだが、ゴールを記述する際の詳細化の度合い(粒度)やゴールの抽象度を決めておくことが重要である。たとえば、ソフトゴールをどこまで詳細化していくかについては良く考える必要がある。また、資源、タスクとソフトゴール間の使い分けをどのように考えるのかは必ずしも明確になっていないと思われる。実際の適用にあたっては、この点をどのように整理していくかがポイントになるだろう。
また、depender、dependum、 dependeeの関係についても受動的に考えるか能動的に考えるかで方向を逆に取り違えてしまう可能性があるので、この点についても分析する際に混乱しないように注意する必要がある。
SDモデルを作成する場合、まずアクタを列挙して、それらの関係を分析することになる。現状モデルは現状のアクタだけを見ることで記述できるが、将来モデルの作成では、モデル化するアクタの範囲を限定するなどの注意が必要だ。この理由は、将来モデルの分析では多様なアクタを構成できる可能性があるので、ある程度の枠をはめて検討しないとモデル化が発散する可能性がある。逆に枠をはめることで効率化できるかもしれないが、必ずしも最適なモデルを抽出できない可能性が出てくるという問題もある。
いずれにしろ最適なモデルの表現はどうすればいいのかについては必ずしも明確な基準が十分ではないように思われるので、今後の研究に期待したい。
参考文献
- [1] Lawrence Chung, Brian Nixon,Eric Yu, John Mylopoulos, Non-Functional Requirements In Software Engineering, Kluwer Academic Publishers, 2000.
- [2] i* an agent-oriented modelling frame- work,http://www.cs.toronto.edu/ km/istar/
- [3] Manuel Kolp, Paolo Giorgini, John Mylopoulos, Information Systems Development through Social Structures, SEKE '02, pp.183-190