2. 機械学習とシミュレーションの融合
シミュレーション&マイニング部 部長
雪島 正敏

機械学習は著しい進化を遂げている。今までは、画像の分類のように、入力データ(画像)とそれに対する出力(何が映っているか)の対応関係を学習するものが主流であったが、世の中にはゴールは分かっているが、そのためのプロセスがわからない問題も存在する。それを解決するための機械学習手法が強化学習と呼ばれる手法である。
AIと機械学習の深化
近年のAI・機械学習の発達には目を見張るものがある。特に深層学習と呼ばれる多層のニューラルネットワークを用いた機械学習手法は、計算能力の向上や学習のためのデータ量の増加、学習アルゴリズムの進化により、他の機械学習手法を圧倒する高い性能を示している。
かつてデータマイニングと呼ばれていた時代、データは過去に何が起こったかを把握(description)し、将来に何が起きるかを予測(prediction)するために用いられていた。そして、これら現状把握と予測をもとに、人が、何かしらの規則や最適化、シミュレーションと呼ばれる手法を用いて、何をすべきかの規範(prescription)を示した(図1)。現在では、誤解を恐れずに言うと、データはAIを学習(機械学習)するための糧として用いられ、さらに、この何をすべきかの規範をも学習することができる。機械学習の言葉でいうと、descriptiveな学習は教師なし学習、predictiveな学習は教師あり学習、そしてprescriptiveな学習は強化学習と呼ばれる。
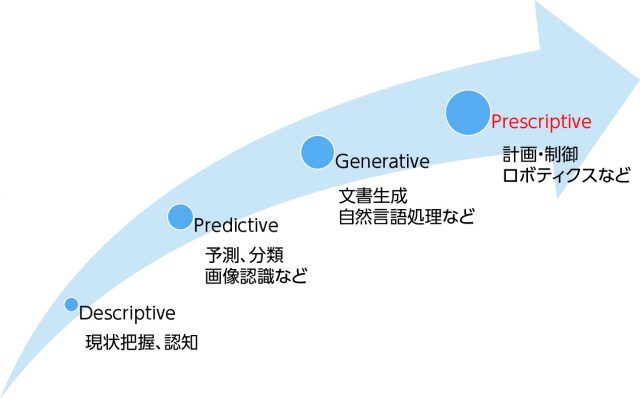
強化学習
機械学習、特に教師付き学習において、データには教師値と呼ばれる正解が必要である。例えば画像の分類を行う場合には、画像データと、そこに映っている『もの』を正解データとしてAIに与え、画像と映っている『もの』との対応関係を学習させることで、画像に何が映っているかを識別させる事ができるようになる。
一方、強化学習では、最終的なゴールは与えられるが、時々刻々の状況においてこのような行動をしたらよいという正解がない中で、時々刻々の状況における適切な行動を学ぶというものである。特徴としては、それぞれの状況に対する正解の行動がない点、時々刻々の行動を行った結果(ゴール)が評価される点、そして行動の結果が次の状態に影響する点である。サッカーを例にとると、ゴールとは文字通り得点する、もしくは試合に勝つことである。それぞれの状況とは、ボール保持者、ボール位置、敵、味方プレーヤーの位置、速度などフィールドの情報から、現在の得失点、経過時間、カード枚数などの試合の進行に関する情報などがある。また、プレーの選択肢としては攻撃側であればパスやドリブル、シュート、守備側であればブロックを作るのか、マークに付くのか、ボールを獲りにいくのか、などの選択肢がある。プレーヤーは、試合を重ねることで、どのような局面でどのようなプレーを選択すべきか、という戦術を修得していく。強化学習では、得点した際に報酬が与えられ、得点までの一連の行動にその報酬を割り当てる。これにより、どの状況でどの行動に価値がある(得点に結びつく)のかを学習する。これを深層学習と組み合わせたものは深層強化学習と呼ばれる。
強化学習とシミュレーション
前述のように、強化学習は正解のない学習方法であるため試行錯誤による探索が必要になる。この時、過去の経験から良いと思う行動を選択しているだけでは、より良い行動を見つけることはできない。一方で、いつまでも新しい行動を探索していてはせっかくの過去の経験を利用しておらず、探索の効率が悪い。これをexploration‐exploitationトレードオフと呼ぶ。
強化学習は既に観測されたデータを用いて(オフライン)学習を行うこともできるが、データの網羅性が低いと学習の効率は悪い。また、実際にデータを観測しながら(オンライン)学習する場合も、行動に対するレスポンスが悪い場合には試行回数を増やすことができず効率が悪い。さらに、選択肢によっては現実の世界で選択することが難しい場合もあり、そのような場合にも学習の効率は悪くなる。そこで登場するのがシミュレーションである。現実を模したシミュレータを用いることで、効率的に多くの試行を行い、シミュレータ上の状況を観測する(サンプリングする)ことができ、また、現実世界では選択できない(しない)選択肢をも選択し、実際に失敗をしてみることで、その選択肢を選択しないことを学習することができる。このように、強化学習とシミュレーションは相性が良い。
シミュレータでの再現が難しい現象(例えば人の振る舞いなど)で観測データが大量にある場合には、surrogate modelと呼ばれる近似モデル(要は状況と行動から次の状況を返す関数)をデータから学習し、シミュレータの代用とすることもできる。
振動制御への適用
強化学習を用いた事例としてNTTファシリティーズ様と取り組んだ事例を紹介する[1]。
建物の揺れを抑える振動制御技術にはいくつか種類がある。その中でアクティブ制御による制振と呼ばれる技術は、建物に粘性系ダンパーと連結した電動アクチュエータを取り付け、電動アクチュエータでダンパーを押したり引いたりすることで建物の揺れを制御する仕組みである。
今回のシステムは、ダンパーと電動アクチュエータのほか、アクチュエータの制御装置(AI)、そして揺れを測る加速度センサーで構成されている(図2)。この技術では20階程度の建物に対して、ダンパーや電動アクチュエータなどの機器を5フロア程度設置すれば効果を得ることができることになる。
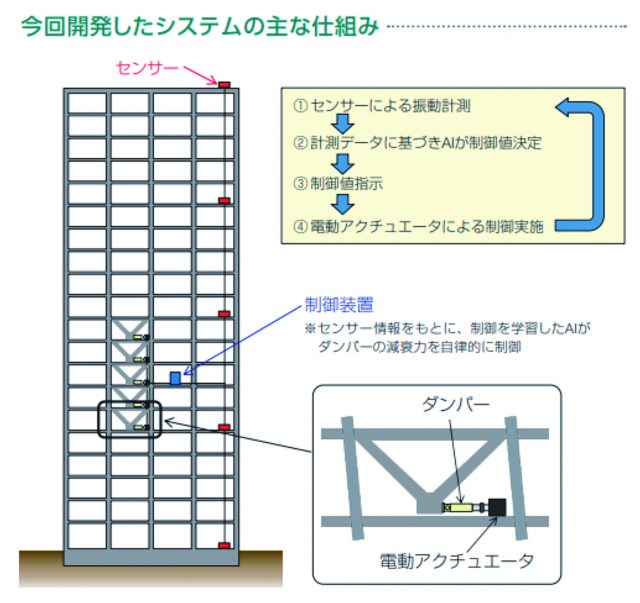
本事例では、様々な地震波に対する建物の挙動をシミュレータを用いて再現し、その制御方法を深層強化学習を用いて学習することで、今までにない優れた制振効果を得ることができた。
[1] ユーザー事例 長周期地震動による超高層建物の揺れを深層強化学習AIで制御
https://www.msi.co.jp/s4/solution/userscase_pdf/nttfacilities.pdf
〈機械学習のことなら下記へ〉
https://www.msi.co.jp/technology/machinelearning.html