3. AI音声認識を活用した次世代ビジネスの展開
アプリケーション&コンテンツサービス部
AI 推進室長 三竹 保宏

本レポートでは、ビジネスの現場で実際にAIが活用されている事例を、そのビジネスインパクトや課題も含めてご紹介していく。今回は、Deep Learning(深層学習)により精度が向上したAI音声認識を活用した実ビジネスの動向についてお伝えする。
音声認識におけるAI技術の活用
コンピュータによる音声認識は古くからある技術で、NTTの研究所においても、数十年にわたって研究が続けられている。前回のレポートでDeep Learning(深層学習)の活用によって映像解析の精度が飛躍的に向上したことをお伝えしたが、音声認識の分野でも同様の取り組みが進んでいる。
Deep Learningを活用した音声認識の仕組みについて簡単に説明する。
音声認識は、通常、音響モデル、言語モデル、単語リストの3つを組み合わせて実現される(図1)。
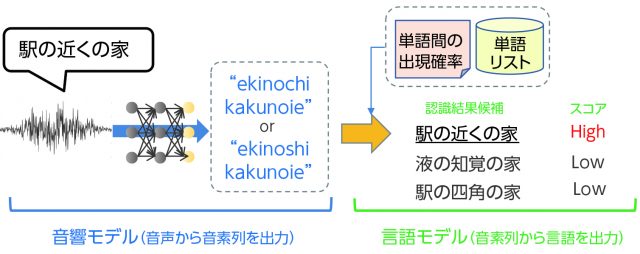
音響モデルは、音声(音の波形)を入力にして、ニューラルネットでその音素を分析して出力する。図1の例で言えば、「駅の近くの家」という音声を「ekinochikakunoie」または「ekinoshikakunoie」という音素列である可能性が高いと分析して出力する。
言語モデルは、「駅」「液」「近く」「知覚」「四角」「家」といった単語をリストとして持ちながら、上記の音素列を、「液の知覚の家」や「駅の四角の家」ではなく、「駅の近くの家」という文であることを、隣り合わせる単語の出現確率等から判定して、音声認識結果を出力する。
この仕組みを理解すれば、音声認識技術の実用化での課題についても理解できると思う。例えば、方言の音声認識に対応しようとすれば、標準語とは異なる音響モデルと言語モデルの組み込みが新たに必要になる。業界特有の用語が多く使われる業務での音声認識の場合にも、認識精度を向上させる際には個別の言語モデルの作成が必要になる。このようにして、「音声認識は個別のチューニングに時間がかかる」、「モデルのチューニングができる技術者が限られるので、一度に多くの案件には対応できない」といったビジネス推進上の課題が生まれている。
研究面では、音声認識の全ての処理をAIで行う方法として、雑音や方言等の音声のゆらぎも含めて音声の入力から認識結果の出力まで、一つの統合されたニューラルネットで処理をするEnd-Endの音声認識の研究も行われているが、現在はまだ実用化には至っていない。(Google等で既に実装されている可能性が無いとは言えない)
AI音声認識を活用したビジネスの拡大
音素の識別にDeep Learningが活用されたことで、音声認識の精度は近年大きく向上し、既に多くのサービスが世の中に展開されている。
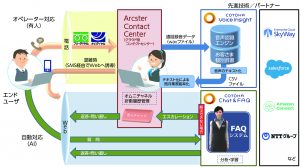
スマホに搭載されているSiri等の音声認識エンジンやGoogle Home等のAIスピーカー、家電やカーナビ等での音声インターフェースが身近な例であるが、ビジネス向けの用途で、顧客からの電話での問い合わせに対応するコンタクトセンタ等でも音声認識の活用が進んでいる。
コンタクトセンタで利用されているNTT研究所の音声認識エンジンは、人と人のやりとり(長文での自然発話)を対象とした汎用モデルをベースとして、NTTグループ各社のコンタクトセンタの通話データを活用して追加チューニングを行った「通信業界向け音声認識モデル」など、業界別モデルの構築も行われている。
コンタクトセンタで音声認識を活用する用途としては、オペレーターの応対をスーパーバイザーが引き継ぐ際に、それまでの応対状況を目視で確認する用途や、応対中に禁止ワード等が発言された際にリアルタイムで検知する、といった用途で応対現場でのニーズがある。
リアルタイム以外のニーズでは、応対状況をテキストデータで蓄積することで、後から応対内容を確認したい時に、通話録音データを聞き直すことなく、テキストベースで簡単に検索できることで業務効率化を図るニーズや、テキストデータから、オペレーター毎の応対時間や応対内容の分析をすることで、コンタクトセンタの運営の高度化/効率化に役立てるといったニーズがある。
NTTグループのサービスでは、オンプレミス型のForesight Voice Mining(NTTテクノクロス社)がリアルタイム型の音声認識サービスとして導入実績を拡大している。
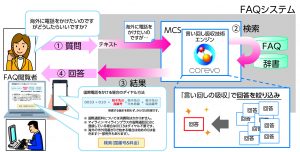
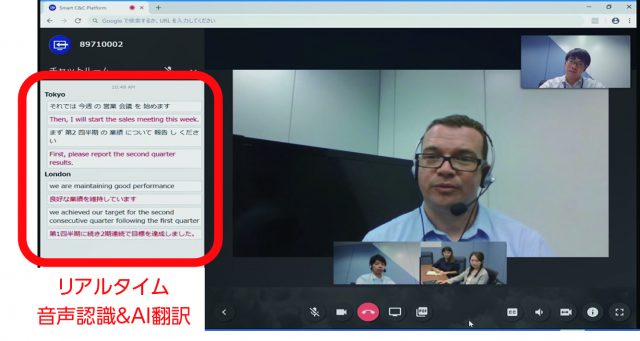
NTTコムでは、リアルタイム以外の利用ニーズを想定して、通話録音装置の音声ファイルをテキスト化して応対状況等のデータの見える化を行うCOTOHA Voice Insight(仮称)を、2019年度当初に提供予定である。COTOHA Voice Insightは、クラウド上で動くCOTOHA音声認識API(2018年度内に商用提供予定)を利用する。COTOHA音声認識APIは、コンタクトセンタ向けの活用だけではなく、COTOHA Translator(AI翻訳)と組み合わせて、Web会議の中で音声認識した内容をリアルタイムで翻訳して多言語会議を可能にするソリューション(図2)や、店頭での販売員の顧客応対を音声認識でテキスト化して接客業務の向上に役立てるソリューション等への活用を予定している。
実ビジネスでの課題としては、個別チューニングを行う際の稼働に加えて、音声データの収集が挙げられる。精度向上のチューニングに必要な学習データとなる音声データを、顧客の承諾を取り、個人情報の扱いに問題のない形で収集し蓄積する取り組みを継続的に進めていく必要がある。
AI音声認識の今後の展開としては、技術面では、音声を文字列に変えるだけではなく、音声から推測できる感情や男性/女性といった属性を付加情報として音声認識結果に追加する仕組みや、疑問文や肯定/否定のトーンを音声から判定する仕組みの研究が既に進んでいる。
音声認識の適用領域は広く、手と目を使わない/使えないシーンでの入力インターフェースとして、医療や介護の現場、建築現場、家事、育児、運転中、等々の様々なシーンでの活用が今後更に広がっていくことが想定される。コンタクトセンタ等でのAIによる自動応対では、既に簡単なシナリオの応答はAI音声認識とAI自動応答システムの組み合わせで実現されているが、今後、人間の発話の意図や内容をより深く理解するAIシステムの開発が進めば、ロボットやConnected Carと連動したより高度なAI自動応答が実現することが期待される。
<AI活用のことなら下記へ>
ai-strategy-ac@ntt.com